
|
Gen-Searcher: Reinforcing Agentic Search for Image Generation
arXiv 2026
Kaituo Feng, Manyuan Zhang, Shuang Chen, Yunlong Lin, Kaixuan Fan, Yilei Jiang, Hongyu Li, Dian Zheng, Chenyang Wang, Xiangyu Yue
First work to explore training a deep research agent for generation.
Paper
Code
|
|
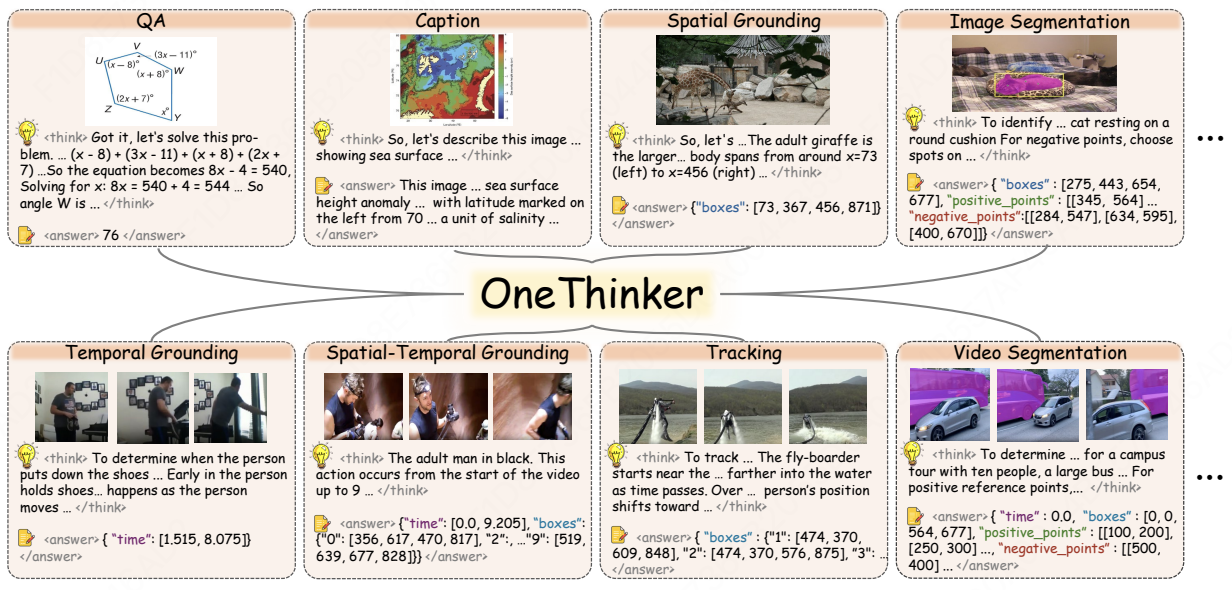
OneThinker: All-in-one Reasoning Model for Image and Video
CVPR 2026
Kaituo Feng, Manyuan Zhang, Hongyu Li, Kaixuan Fan, Shuang Chen, Yilei Jiang, Dian Zheng, Peiwen Sun, Yiyuan Zhang, Haoze Sun, et al
Improves 10 fundamental visual tasks across 31 benchmarks by RL post-training.
Paper
Code
|
|
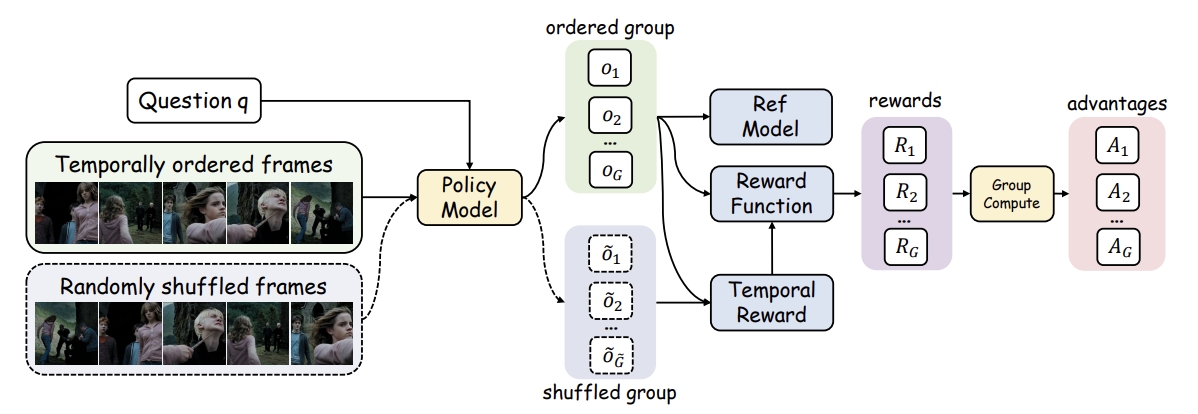
Video-R1: Reinforcing Video Reasoning in MLLMs
NeurIPS 2025
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, Xiangyu Yue
Explore the R1 paradigm for eliciting video reasoning within MLLMs.
NeurIPS 2025 Most Influential Paper Top 10
Paper
Code
|

|
AdaTooler-V: Adaptive Tool-Use for Images and Videos
ACL 2026 Findings
Chaoyang Wang, Kaituo Feng†, Dongyang Chen, Zhongyu Wang, Zhixun Li, Sicheng Gao, Meng Meng, Xu Zhou, Manyuan Zhang, Yuzhang Shang, Xiangyu Yue (†project leader)
Training adaptive tool-use visual agent via RL.
Paper
Code
|

|
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
NeurIPS 2025
Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, Tieniu Tan
Achieveing o3-like thinking for spatial reasoning across images and videos.
Paper
Code
|
|
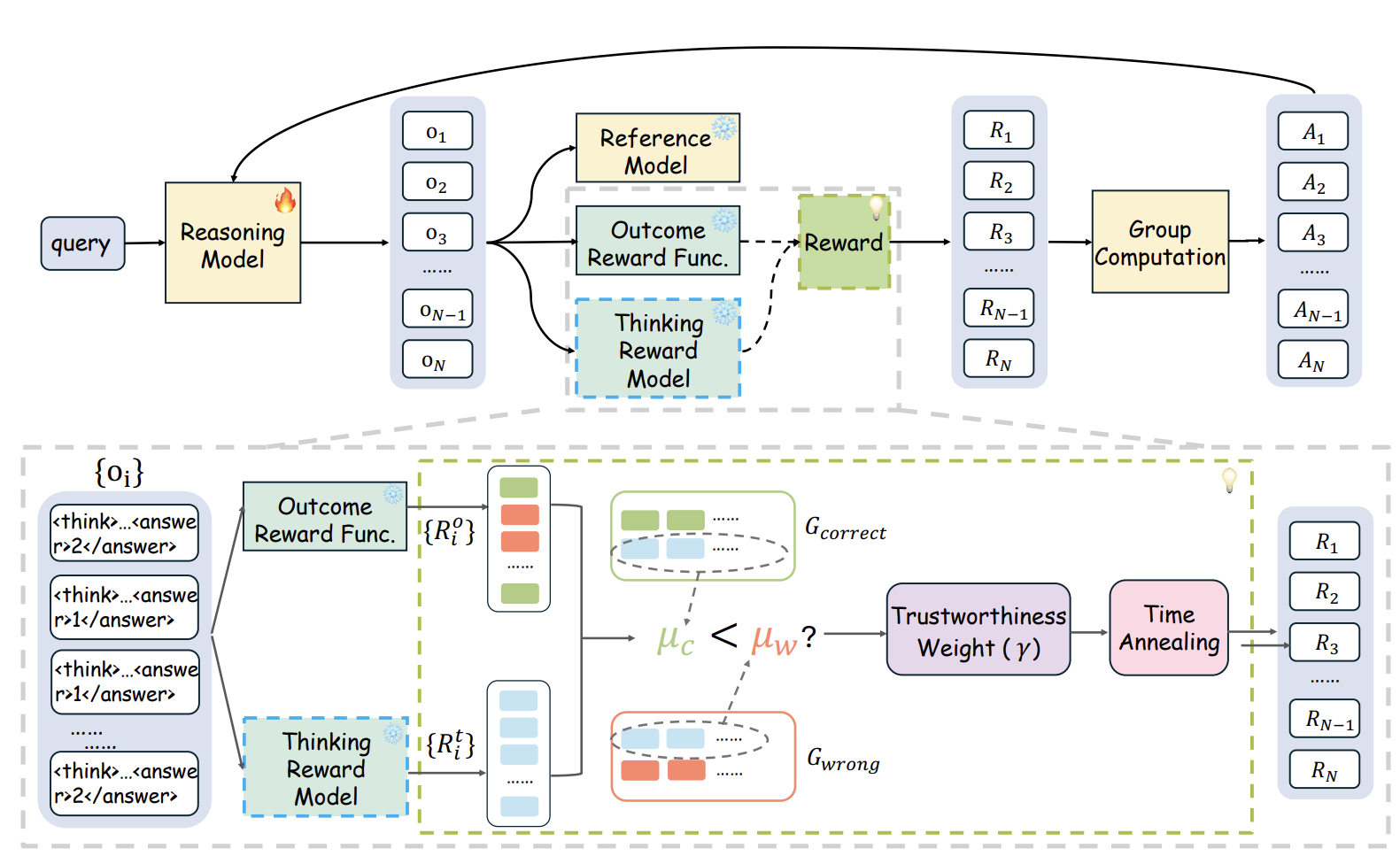
SophiaVL-R1: Reinforcing MLLMs Reasoning with Thinking Reward
ICLR 2026
Kaixuan Fan*, Kaituo Feng*, Haoming Lyu, Dongzhan Zhou, Xiangyu Yue (*equal contribution)
Intergrating thinking-level reward to address the phenomenon of "wrong thinking, correct answer".
Paper
Code
|
|
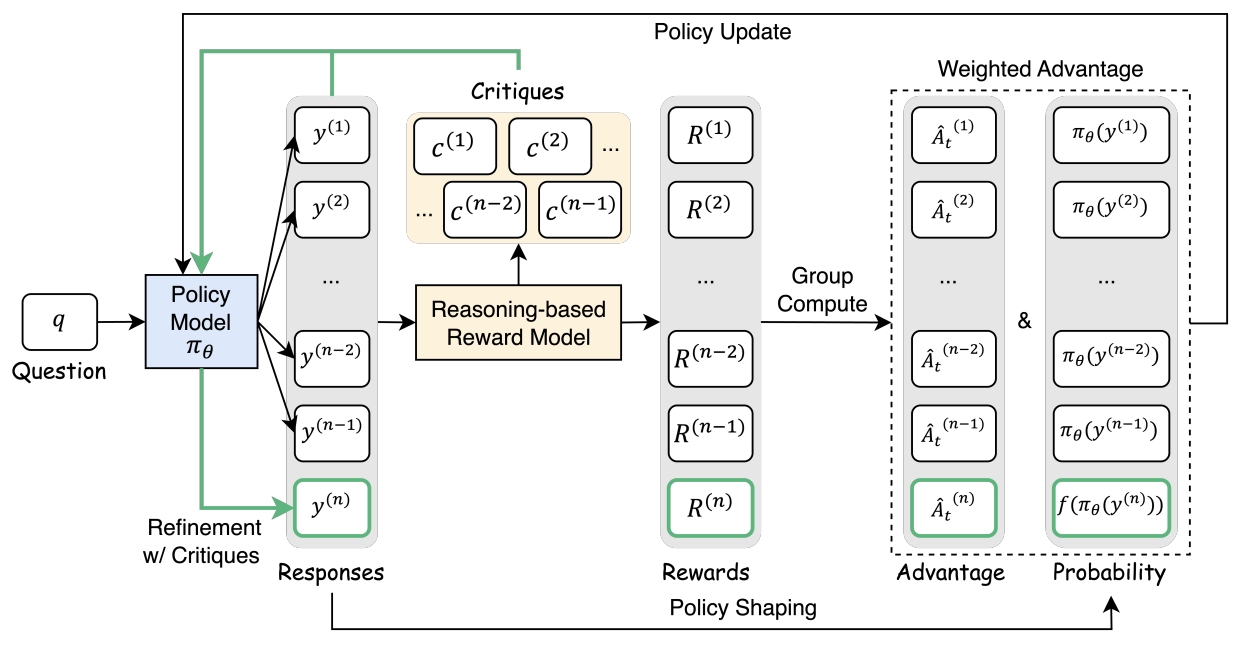
Critique-GRPO: Advancing LLM Reasoning with Natural Language and Numerical Feedback
arXiv 2025
Xiaoying Zhang, Hao Sun, Yipeng Zhang, Kaituo Feng, Chaochao Lu, Chao Yang, Helen Meng
Using external critiques as language feedback for improving reasoning
Paper
Code
|

|
AV-Odyssey: Can Your Multimodal LLMs Really Understand Audio-Visual Information?
ACL 2026
Kaixiong Gong*, Kaituo Feng*, Bohao Li*, Yibing Wang, Mofan Cheng, Shijia Yang, Jiaming Han, Benyou Wang, Yutong Bai, Zhuoran Yang, Xiangyu Yue (*equal contribution)
We propose a comprehensive benchmark for evaluating audio-visual understanding abilities of MLLMs.
Paper
Code
|
|
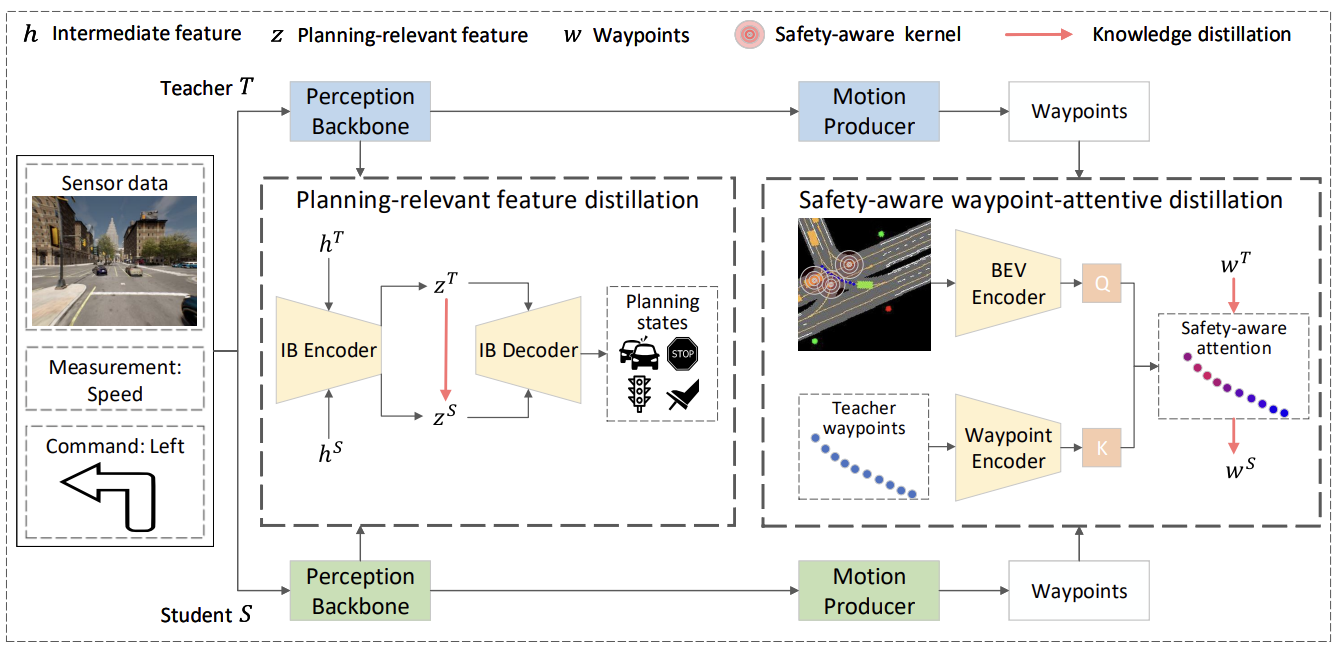
On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
CVPR 2024
Kaituo Feng, Changsheng Li, Dongchun Ren, Ye Yuan, Guoren Wang
We constitute the first attempt to explore a knowledge distillation method to compress end-to-end autonomous driving planners.
Paper
Code
|
|
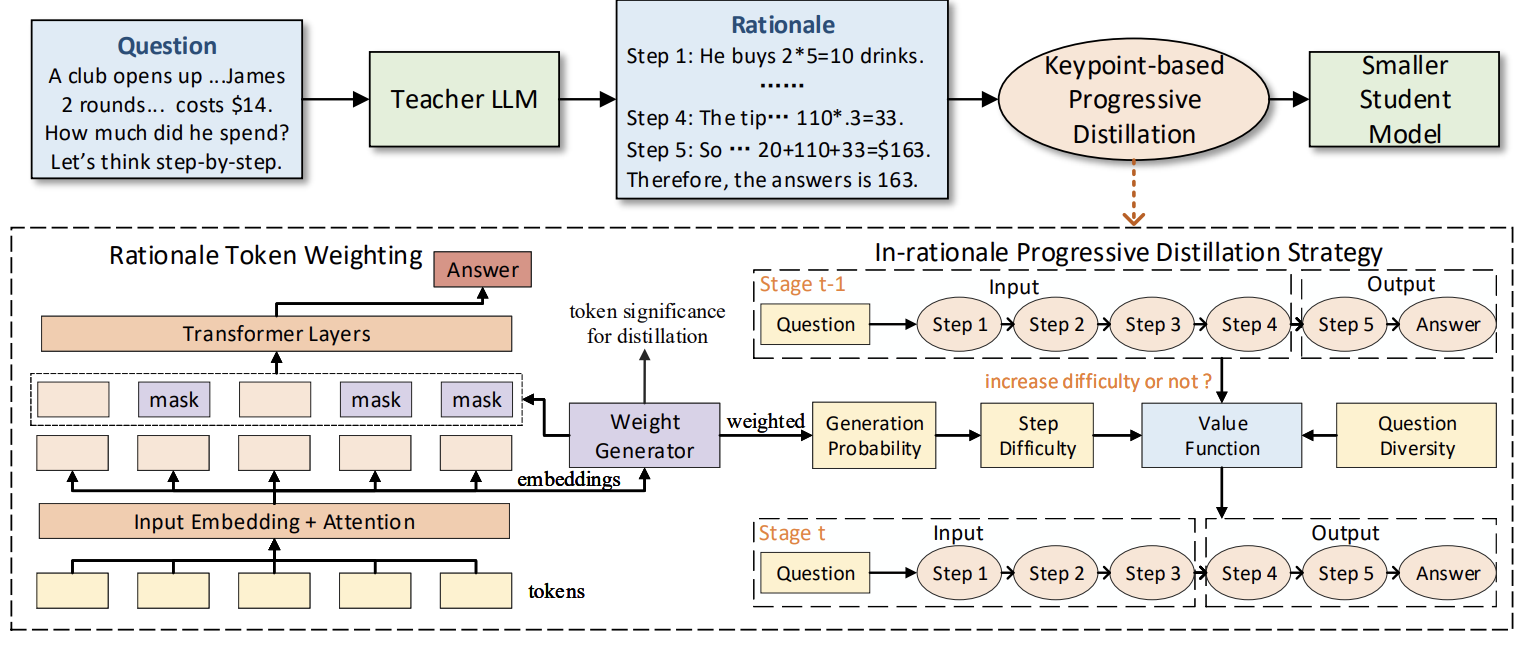
Keypoint-based Progressive Chain-of-Thought Distillation for LLMs
ICML 2024
Kaituo Feng, Changsheng Li, Xiaolu Zhang, Jun Zhou, Ye Yuan, Guoren Wang
We propose a new compression method to progressively distill the emergent reasoning capabilities of LLMs into smaller models, as well as encouraging the precise mimicry of significant tokens.
Paper
|
|
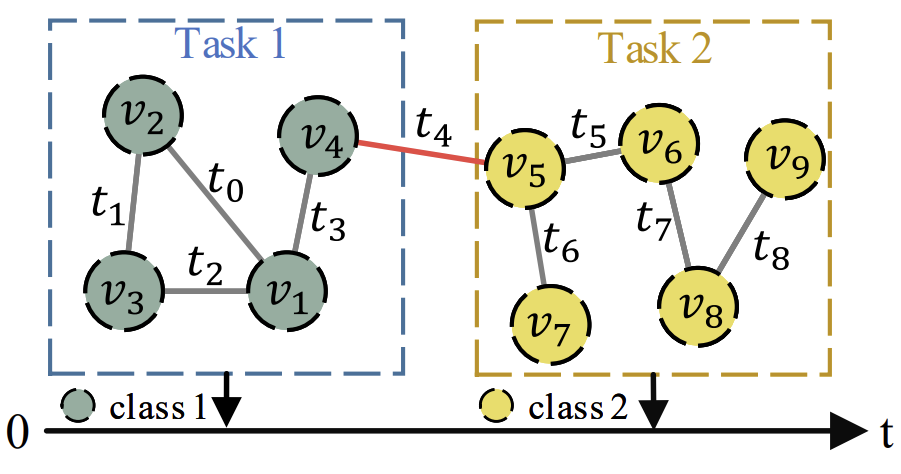
Towards Open Temporal Graph Neural Networks
ICLR 2023, Oral, 90/4922
Kaituo Feng, Changsheng Li, Xiaolu Zhang, Jun Zhou
We propose the first class-incremental learning for temporal GNNs, allowing temporal graphs to evolve in the real-world scenarios with an open class set
Paper
Code
|
|
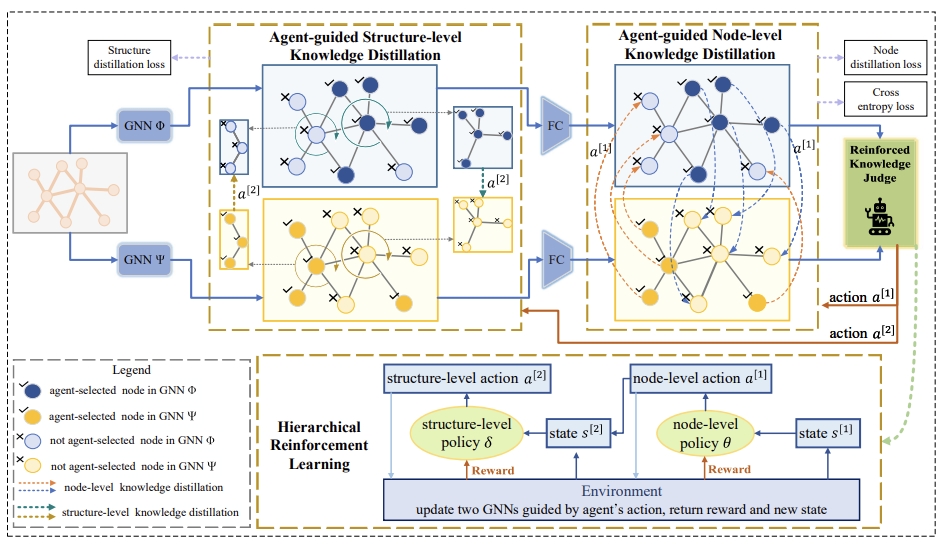
Shared Growth of Graph Neural Networks via Prompted Free-Direction Knowledge Distillation
IEEE TPAMI, KDD 2022
Kaituo Feng, Yikun Miao, Changsheng Li, Ye Yuan, Guoren Wang
We utilize reinforcement learning to exchange beneficial knowledge between two GNNs
Paper
|
